正则表达式中的坑
什么是正则表达式?
正则表达式是计算机科学概念,用简单字符串来描述、匹配文中全部匹配指定格式的字符串,现在很多文本编辑器都支持用正则表达式搜索、取代匹配指定格式的字符串。正则表达式可以使用一些特定的元字符来检索、匹配以及替换符合规则的字符串。
正则表达式引擎
正则表达式是一个用正则符号写出的公式,程序对这个公式进行语法分析,建立一个语法分析树,再根据这个分析树结合正则表达式的引擎生成执行程序(这个执行程序我们把它称作状态机,也叫状态自动机),用于字符匹配。而这里的正则表达式引擎就是一套核心算法,用于建立状态机。目前实现正则表达式引擎的方式有两种:
- DFA自动机(Deterministic Final Automaton 确定有限状态自动机)
- NFA自动机(Non deterministic Finite Automaton 非确定有限状态自动机)
构造DFA自动机的代价远大于NFA自动机,但DFA自动机的执行效率高于NFA自动机。
假设一个字符串的长度是n,如果用DFA自动机作为正则表达式引擎,则匹配的时间复杂度为O(n);如果用NFA自动机作为正则表达式引擎,由于NFA自动机在匹配过程中存在大量的分支和回溯,假设NFA的状态数为s,则该匹配算法的时间复杂度为O(ns)。
NFA自动机的优势是支持更多功能。例如,捕获group、环视、占有优先量词等高级功能。这些功能都是基于子表达式独立进行匹配,因此在编程语言里,使用的正则表达式库都是基于NFA实现的。
NFA自动机的匹配流程
NFA自动机会读取正则表达式的每一个字符,拿去和目标字符串匹配,匹配成功就换正则表达式的下一个字符,反之就继续和目标字符串的下一个字符进行匹配。
回溯机制
回溯是指在正则表达式引擎尝试匹配字符串时,当当前的匹配方案无法满足整个正则表达式的要求时,引擎会回退到之前的某个状态,尝试其他可能的匹配方案,直到找到满足条件的匹配结果或者所有可能性都尝试完毕为止。
贪婪模式(Greedy)
正则表达式的贪婪模式是指在匹配字符串时,尽可能多地匹配目标字符串的特性。换句话说,贪婪模式会尽量匹配更长的子串,直到无法再匹配为止。正则表达式中的贪婪模式通常是通过量词实现的,例如 *、+、?、{n,} 等。这些量词表示匹配前面的元素零次或多次、一次或多次、零次或一次、至少 n 次等,它们默认都是贪婪的,会尽可能多地匹配目标字符串。
连续出现1-3次字符a,然后跟着字符 b会被匹配
a{1,3}b
假设字符串是aabb贪婪模式会匹配整个字符串aab。
贪婪模式的匹配流程
- 匹配第一个字符
a,与aabb的第1个字符a匹配(成功) - 贪婪模式会尽可能多地匹配
a,第2次尝试匹配a,与aabb的第2个字符a匹配(成功) - 贪婪模式会尽可能多地匹配
a,第3次尝试匹配,与aabb的第3个字符b匹配(失败) - 由于上次匹配失败了会发生回溯,读取正则的下一个匹配符
b,再次与aabb的第3个字符b匹配 - 匹配完成结束
懒惰模式(Reluctant)
与贪婪模式相反,懒惰模式尽可能少地匹配目标字符串,即匹配最短的可能子串。懒惰模式通常通过在量词后面加上问号?来表示。但是懒惰模式并不能完全避免回溯。假设使用ab{1,3}?c去匹配abbc,这是可以匹配成功的,这里会发生回溯。使用c去匹配abbc的第三个字母b无法匹配就发生回溯,再次使用c和abbc的第四个字母c做匹配。
连续出现1-3次字符a,然后跟着字符 b会被匹配
a{1,3}?b
假设字符串是aabb贪婪模式会匹配整个字符串ab。
懒惰模式的匹配流程
- 匹配第一个字符
a,与aabb的第一个字符a匹配(成功) - 读取正则的下一个匹配符
b,与aabb的第2个字符a匹配(失败) - 继续使用匹配符
b,与aabb的第3个字符b匹配(成功) - 匹配完成结束
独占模式(Possessive)
同贪婪模式一样,独占模式一样会最大限度地匹配更多内容;不同的是,在独占模式下,匹配失败就会结束匹配,不会发生回溯问题。
匹配a开头接着连续1-3个b,最后以bc结尾的字符串
ab{1,3}+bc
假设我们要匹配的字符串是abbc,将无法匹配到结果。
独占模式的匹配流程
- 匹配表达式的第一个字符
a,与abbc的第一个字符匹配(成功) - 独占模式会尽可能多地匹配
b,第1次尝试与abbc的第2个字符b匹配(成功) - 独占模式会尽可能多地匹配
b,第2次尝试与abbc的第3个字符b匹配(成功) - 独占模式会尽可能多地匹配
b,第3次尝试与abbc的第3个字符c匹配(失败) - 匹配失败直接结束,不会发生回溯
优化正则表达式
正如上面看到的,使用贪婪模式会尽可能多的匹配,在匹配失败的时候会发生回溯并尝试其他可能的匹配方案,直到找到满足条件的匹配结果或者所有可能性都尝试完毕为止。所以要尽可能少的使用贪婪模式,贪婪模式在匹配未知的字符串时可能发生灾难性回溯。也就是说可能拥有几万甚至上百万种匹配方案,一个表达式回溯上万次将会导致灾难性的后果,比如服务器的CPU被正则表达式吃满。
少用贪婪模式,多用独占模式
贪婪模式会引起回溯问题,可以使用独占模式来避免回溯。
减少分支选择
分支选择表达式比如(PAYMENT|REFUND|SIGN),既匹配支付、退款、或是签约。我们应该尽量少的使用,这与MySQL中不推荐使用in语句有异曲同工之妙。如果真要使用就把最常用的放在前面,比如支付>退款>签约,所以使用上面的表达式是正确的。如果顺序反过来就会导致大量的匹配失败而导致回溯,降低性能。
其次我们还可以提取共用模式,比如(PAYMENTQUERY|PAYMENTNOTIFY),可以优化为PAYMENT(QUERY|NOTIFY),这样也会提高性能,因为NFA自动机会尝试匹配PAYMENT,如果没有找到PAYMENT,就不会再尝试任何方案了。
减少捕获组
用小括号()包裹起来的部分称为捕获组。当正则表达式引擎进行匹配时,捕获组会将匹配的子字符串保存起来,以便后续可以通过反向引用或者程序来获取这些匹配的子字符串。
String reg="(a)(b)(c)";
Matcher testMatch = Pattern.compile(reg).matcher(text);
// 可以使用.group(编号)来获取a、b、c捕获组中的子表达式的值
testMatch.group(0)
但是使用捕获组会降低性能,通常我们很少用到复杂的匹配,如果不需要使用子表达式的值做复杂运算就应该避免使用捕获组,使用非捕获组。在捕获组的小括号前加上?:就可以创建一个非捕获组。比如捕获组(a)(b)(c)转换为非捕获等于(?:a)(?:b)(?:c)。
很多人可能觉得正则用的不多,但是正则是计算机科学概念,已经内置在操作系统和编程语言中。Java的
String.Split()方法就是使用正则匹配字符串的,所以很容易掉进陷阱里。
工具推荐
其实有一些很不错的在线工具可以帮助我们校验表达式的性能,我推荐一个很不错的在线工具:https://regex101.com/
该工具可以选择编程语言并测试正则表达式的性能和正确性。比如下面的正则表达式匹配耗时0.3ms。
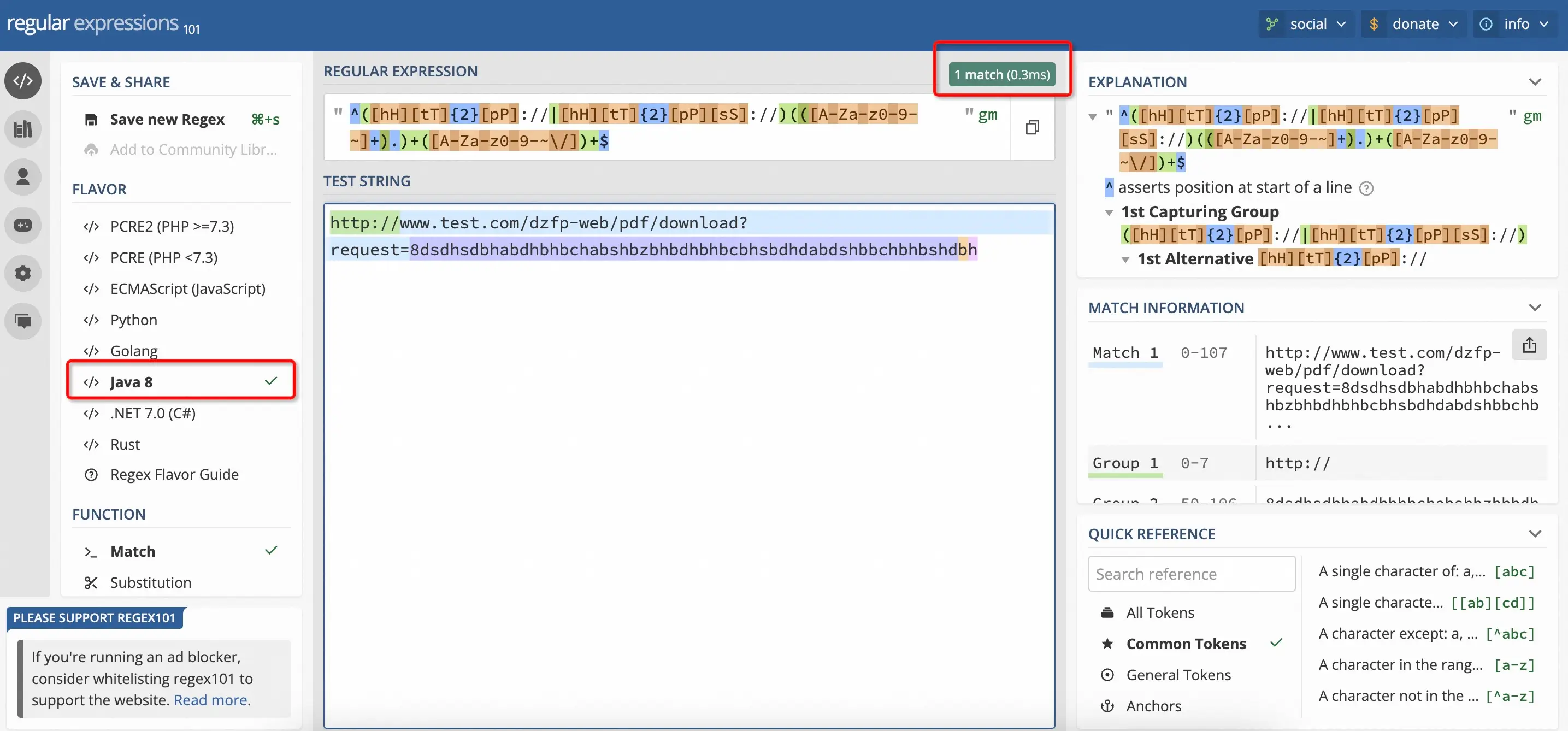
如果是异常情况,比如出现了灾难性回溯,则会直接警告⚠️: