Alibaba COLA架构解析
互联网业务代码都有这几个特点:
- 互联网业务迭代快,工期紧,导致代码结构混乱,几乎没有代码注释和文档。
- 互联网人员变动频繁,很容易接手别人的老项目,新人根本没时间吃透代码结构,紧迫的工期又只能让屎山越堆越大。
- 多人一起开发,每个人的编码习惯不同,工具类代码各用个的,业务命名也经常冲突,影响效率。
- 大部分团队几乎没有时间做代码重构,任由代码腐烂。
每当我们新启动一个代码仓库,都是信心满满,结构整洁。但是时间越往后,代码就变得腐败不堪,技术债务越来越庞大…
这种情况有解决方案吗?也是有的:
- 小组内定期做代码重构,解决技术债务。
- 组内设计完善的应用架构,让代码的腐烂来得慢一些。(当然很难做到完全不腐烂)
- 设计尽量简单,让不同层级的开发都能快速看懂并上手开发,而不是在一堆复杂的没人看懂的代码上堆更多的屎山。
我们今天的主角COLA,就是为了提供一个可落地的业务代码结构规范,让你的代码腐烂的尽可能慢一些,让团队的开发效率尽可能快一些。
COLA是什么
GIthub:https://github.com/alibaba/COLA
COLA是由阿里巴巴的张建飞所提出的一种业务代码架构的最佳实践,并且已经在阿里云脚手架代码生成器中作为一个可选项。
COLA 是 Clean Object-Oriented and Layered Architecture的缩写,代表整洁面向对象分层架构。
在COLA 4.0,也就是目前最新的版本中,作者将COLA拆分为COLA架构(Archetype)和COLA组件(Components)两个部分:
- COLA架构:COLA应用的代码模板。
- COLA组件:提供一些非常有用的通用组件,这些组件可以帮助我们提升研发效率。
两者互不干扰,可以独立使用。
COLA整体架构
首先主要谈谈COLA架构,COLA的官方博文中是这么介绍的:
在平时我们的业务开发中,大部分的系统都需要:
- 接收request,响应response;
- 做业务逻辑处理,像校验参数,状态流转,业务计算等等;
- 和外部系统有联动,像数据库,微服务,搜索引擎等;
正是有这样的共性存在,才会有很多普适的架构思想出现,比如分层架构、六边形架构、洋葱圈架构、整洁架构(Clean Architecture)、DDD架构等等。
这些应用架构思想虽然很好,但我们很多同学还是“不讲Co德,明白了很多道理,可还是过不好这一生”。问题就在于缺乏实践和指导。COLA的意义就在于,他不仅是思想,还提供了可落地的实践。应该是为数不多的应用架构层面的开源软件。
COLA提供了一整套代码架构,拿来即用。 其中包含了很多架构设计思想,包括讨论度很高的领域驱动设计DDD等。
注意:每个人对于架构设计都有着自己的理解。所以对于COLA的架构,本篇文章也仅仅只是我自己对于COLA的粗浅理解,仅供大家参考,如有歧义欢迎在评论区探讨。
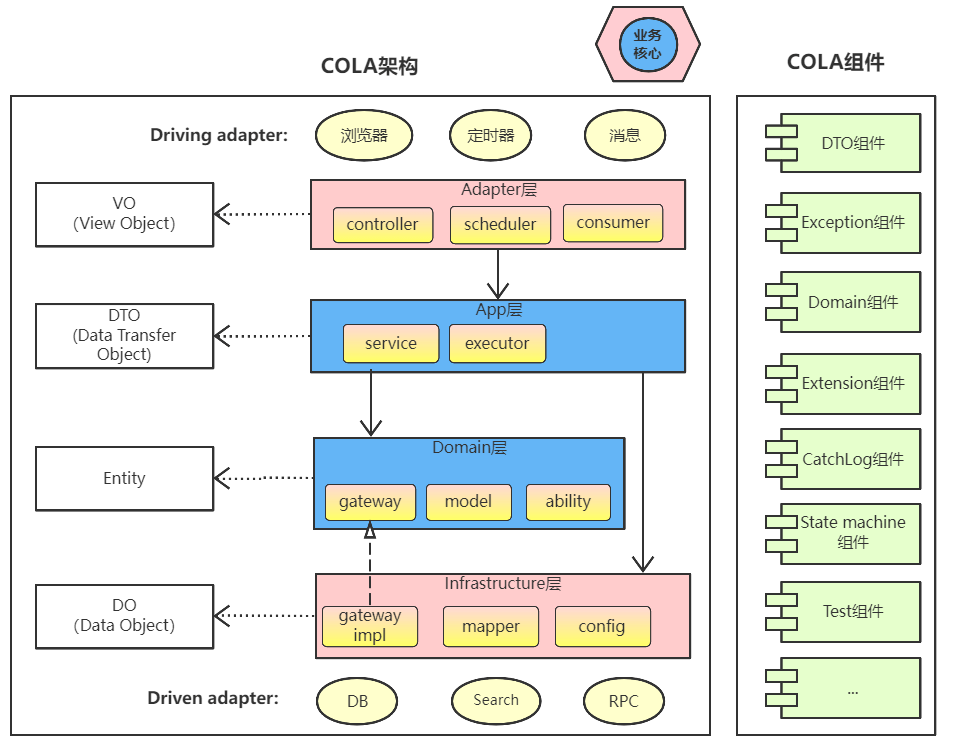
COLA分层架构
官方介绍图:
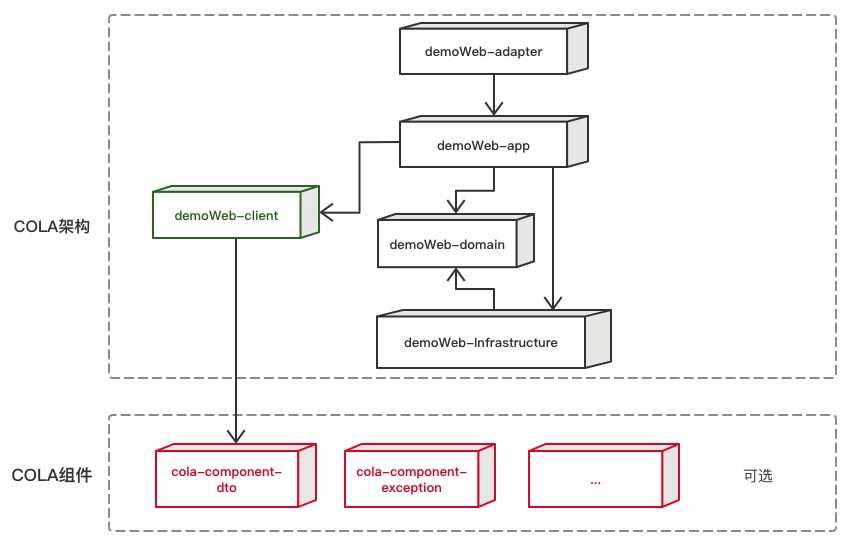
官方还有一个表格,介绍了COLA中每个层的命名和含义:
| 层次 | 包名 | 功能 | 必选 |
|---|---|---|---|
| Adapter layer | web | 处理页面请求的Controller | 否 |
| Adapter layer | wireless | 处理无线端的适配 | 否 |
| Adapter layer | wap | 处理wap端的适配 | 否 |
| App层 | executor | 处理request,包括command和query | 是 |
| App层 | consumer | 处理外部message | 否 |
| App层 | scheduler | 处理定时任务 | 否 |
| Domain层 | model | 领域模型 | 否 |
| Domain层 | ability | 领域能力,包括DomainService | 否 |
| Domain层 | gateway | 领域网关,解耦利器 | 是 |
| Infra层 | gatewayimpl | 网关实现 | 是 |
| Infra层 | mapper | ibatis数据库映射 | 否 |
| Infra层 | config | 配置信息 | 否 |
| Client SDK | api | 服务对外透出的API | 是 |
| Client SDK | dto | 服务对外的DTO | 是 |
COLA组件含义:
| 组件名称 | 功能 | 依赖 |
|---|---|---|
cola-component-dto |
定义了DTO格式,包括分页 |
无 |
cola-component-exception |
定义了异常格式, 主要有BizException和SysException |
无 |
cola-component-statemachine |
状态机组件 | 无 |
cola-component-domain-starter |
Spring托管的领域实体组件 |
无 |
cola-component-catchlog-starter |
异常处理和日志组件 | exception、dto组件 |
cola-component-extension-starter |
扩展点组件 | 无 |
cola-component-test-container |
测试容器组件 | 无 |
从Demo说起
主Pom:
<modules>
<module>demo-web-client</module>
<module>demo-web-adapter</module>
<module>demo-web-app</module>
<module>demo-web-domain</module>
<module>demo-web-infrastructure</module>
<module>start</module>
</modules>
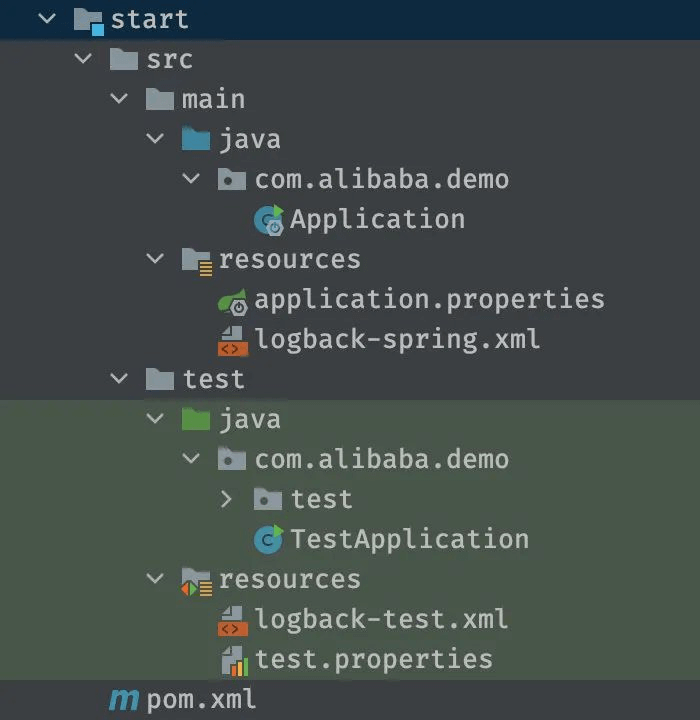
start层
该模块作为整个应用的启动模块(通常是一个SpringBoot应用),只承担启动项目和全局相关配置项的存放职责。
将启动独立出来,好处是清晰简洁,也能让新人一眼就看出如何运行项目,以及项目的一些基础依赖。
代码结构如下:
adapter层
接下来我们按照之前架构图从上到下的顺序,一个个看。
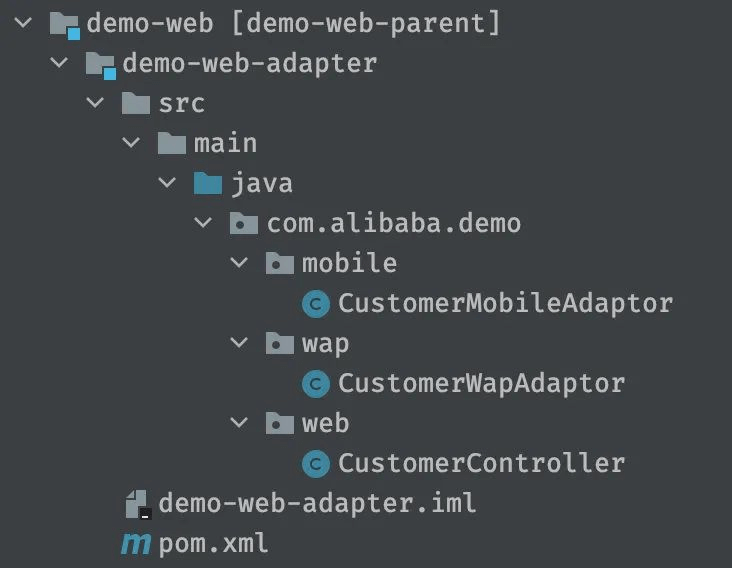
首先是demo-web-adapter模块,可以理解为平时我们用的controller层(对于Web应用来说)。
在COLA官方博客中,也能找到如下的描述:
Controller这个名字主要是来自于MVC,因为是MVC,所以自带了Web应用的烙印。然而,随着mobile的兴起,现在很少有应用仅仅只支持Web端,通常的标配是Web,Mobile,WAP三端都要支持。
cilent层
有了我们说的controller层,接下来有的小伙伴肯定就会想,是不是service层了。
是,也不是。
传统的Web应用中,完全可以只有一个service层给controller层调用,但是作为一个业务应用,除非你真的只是个前端页面的无情吐数据机器,否则很大可能性你的应用会有很多其他上下游调用方,并且你需要提供接口给他们。
这时候你给他们的不应该是一个Web接口,应该是RPC调用的服务层接口。
所以在COLA中,你的adapter层,调用了client层,client层中就是你服务接口的定义。
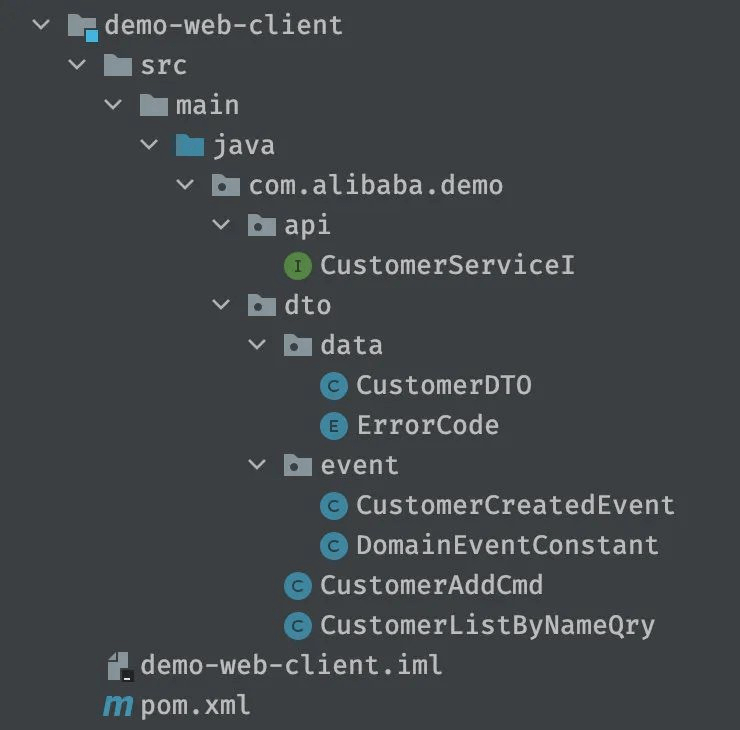
从上图中可以看到,client包里有:
- api文件夹:存放服务接口定义
- dto文件夹:存放传输实体
注意,这里只是服务接口定义,而不是服务层的具体实现,所以在adapter层中,调用的其实是client层的接口:
@RestController
public class CustomerController {
@Autowired
private CustomerServiceI customerService;
@GetMapping(value = "/customer")
public MultiResponse<CustomerDTO> listCustomerByName(@RequestParam(required = false) String name){
CustomerListByNameQry customerListByNameQry = new CustomerListByNameQry();
customerListByNameQry.setName(name);
return customerService.listByName(customerListByNameQry);
}
}
而最终接口的具体实现逻辑放到了app层。
@Service
@CatchAndLog
public class CustomerServiceImpl implements CustomerServiceI {
@Resource
private CustomerListByNameQryExe customerListByNameQryExe;
@Override
public MultiResponse<CustomerDTO> listByName(CustomerListByNameQry customerListByNameQry) {
return customerListByNameQryExe.execute(customerListByNameQry);
}
}
app层
接着上面说的,我们的app模块作为服务的实现,存放了各个业务的实现类,并且严格按照业务分包,这里划重点,是先按照业务分包,再按照功能分包的。
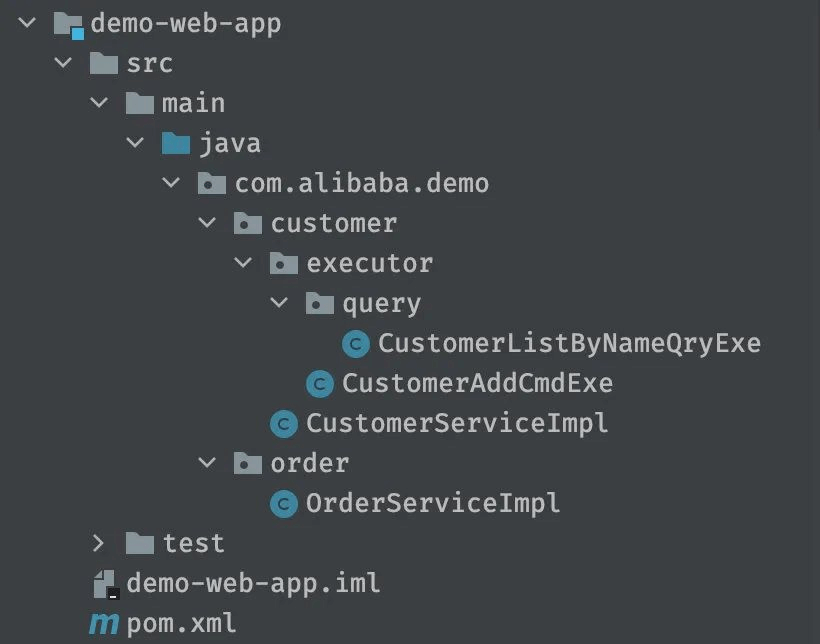
customer和order分别对应了消费着和订单两个业务子领域。里面是COLA定义app层下面三种功能:
| App层 | executor | 处理request,包括command和query | 是 |
|---|---|---|---|
| App层 | consumer | 处理外部message | 否 |
| App层 | scheduler | 处理定时任务 | 否 |
可以看到,消息队列的消费者和定时任务,这类平时我们业务开发经常会遇到的场景,也放在app层。
domain层
接下来便是domain,也就是领域层,先看一下领域层整体结构:
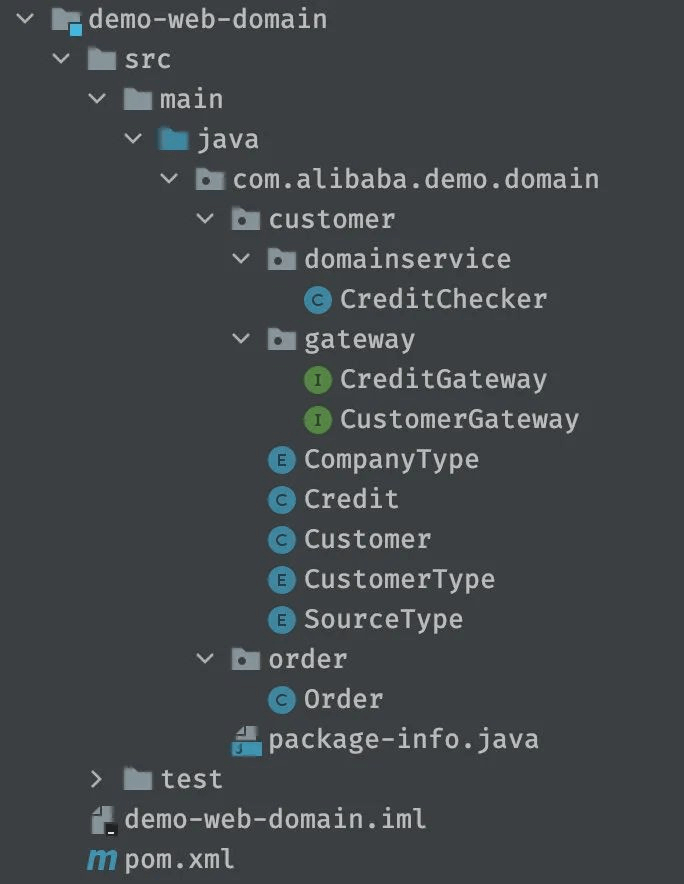
可以看到,首先是按照不同的领域(customer和order)分包,里面则是三种主要的文件类型:
领域实体:
实体模型可以是充血模型(自行了解),例如官方示例里的Customer.java如下:
@Data
@Entity
public class Customer{
private String customerId;
private String memberId;
private String globalId;
private long registeredCapital;
private String companyName;
private SourceType sourceType;
private CompanyType companyType;
public Customer() {
}
public boolean isBigCompany() {
return registeredCapital > 10000000; //注册资金大于1000万的是大企业
}
public boolean isSME() {
return registeredCapital > 10000 && registeredCapital < 1000000; //注册资金大于10万小于100万的为中小企业
}
public void checkConfilict(){
//Per different biz, the check policy could be different, if so, use ExtensionPoint
if("ConflictCompanyName".equals(this.companyName)){
throw new BizException(this.companyName+" has already existed, you can not add it");
}
}
}
领域能力:
domainservice文件夹下,是领域对外暴露的服务能力,如上图中的CreditChecker
领域网关:
gateway文件夹下的接口定义,这里的接口你可以粗略的理解成一种SPI,也就是交给infrastructure层去实现的接口。
例如
CustomerGateway里定义了接口getByById,要求infrastructure的实现类必须定义如何通过消费者Id获取消费者实体信息,而infrastructure层可以实现任何数据源逻辑,比如,从MySQL获取,从Redis获取,还是从外部API获取等等。
public interface CustomerGateway {
public Customer getByById(String customerId);
}
在示例代码的CustomerGatewayImpl(位于infrastructure层)中,CustomerDO(数据库实体)经过MyBatis的查询,转换为了Customer领域实体,进行返回。完成了依赖倒置。
@Component
public class CustomerGatewayImpl implements CustomerGateway {
@Autowired
private CustomerMapper customerMapper;
public Customer getByById(String customerId){
CustomerDO customerDO = customerMapper.getById(customerId);
//Convert to Customer
return null;
}
}
infrastructure层
最后是我们的infrastructure也就是基础设施层,这层有我们刚才提到的gatewayimpl网关实现,也有MyBatis的mapper等数据源的映射和config配置文件。
| Infra层 | gatewayimpl | 网关实现 | 是 |
|---|---|---|---|
| Infra层 | mapper | ibatis数据库映射 | 否 |
| Infra层 | config | 配置信息 | 否 |
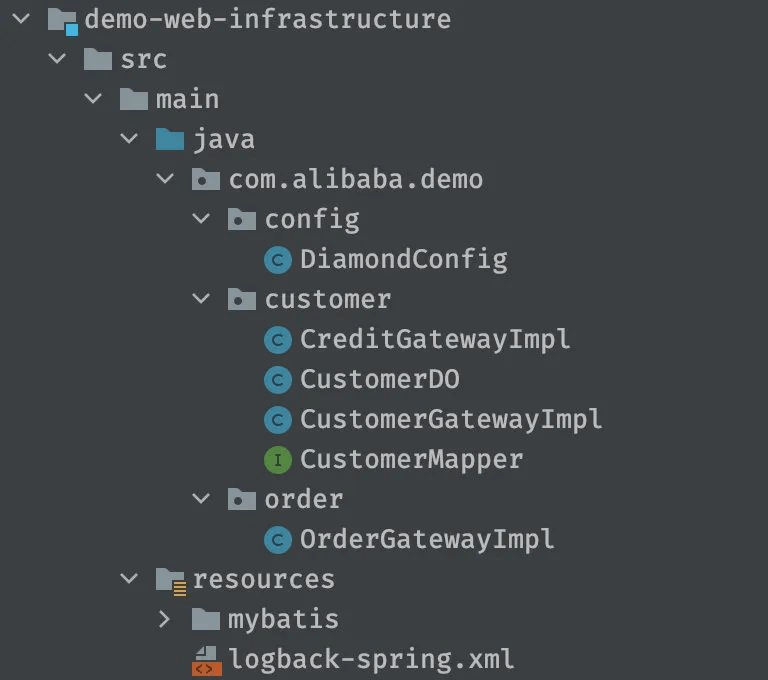
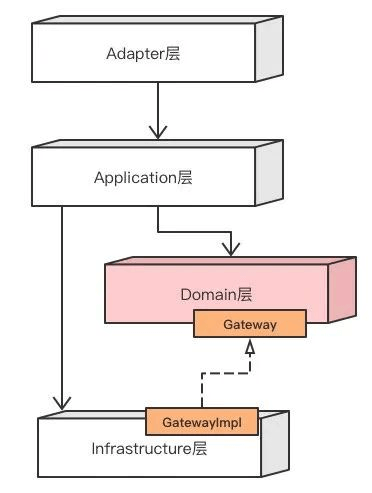
所有层讲完了,COLA4.0很简单明了,最后,在引用一段官方介绍博客原文来总结COLA的层级:
适配层(Adapter Layer):负责对前端展示(web,wireless,wap)的路由和适配,对于传统B/S系统而言,adapter就相当于MVC中的controller;
应用层(Application Layer):主要负责获取输入,组装上下文,参数校验,调用领域层做业务处理,如果需要的话,发送消息通知等。层次是开放的,应用层也可以绕过领域层,直接访问基础实施层;
领域层(Domain Layer):主要是封装了核心业务逻辑,并通过领域服务(Domain Service)和领域对象(Domain Entity)的方法对App层提供业务实体和业务逻辑计算。领域是应用的核心,不依赖任何其他层次;
基础实施层(Infrastructure Layer):主要负责技术细节问题的处理,比如数据库的CRUD、搜索引擎、文件系统、分布式服务的RPC等。此外,领域防腐的重任也落在这里,外部依赖需要通过gateway的转义处理,才能被上面的App层和Domain层使用。
COLA架构的特色
说完了分层架构,我们再来回顾下上面提到的COLA架构的几个特色的设计
领域与功能的分包策略
也就是下面这张图的意思,先按照领域分包,再按照功能分包,这样做的其中一点好处是能将腐烂控制在该业务域内。
比如消费者customer和订单order两个领域是两个后端开发并行开发,两个人对于dto,util这些文件夹的命名习惯都不同,那么只会腐烂在各自的业务包下面,而不会将dto,util,config等文件夹放在一起,极容易引发文件冲突。
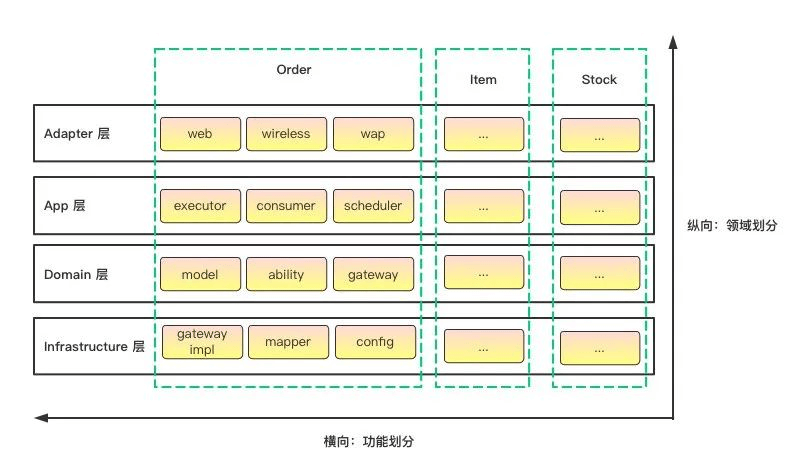
前面的包定义,都是功能维度的定义。为了兼顾领域维度的内聚性,我们有必要对包结构进行一下微调,即顶层包结构应该是按照领域划分,让领域内聚。
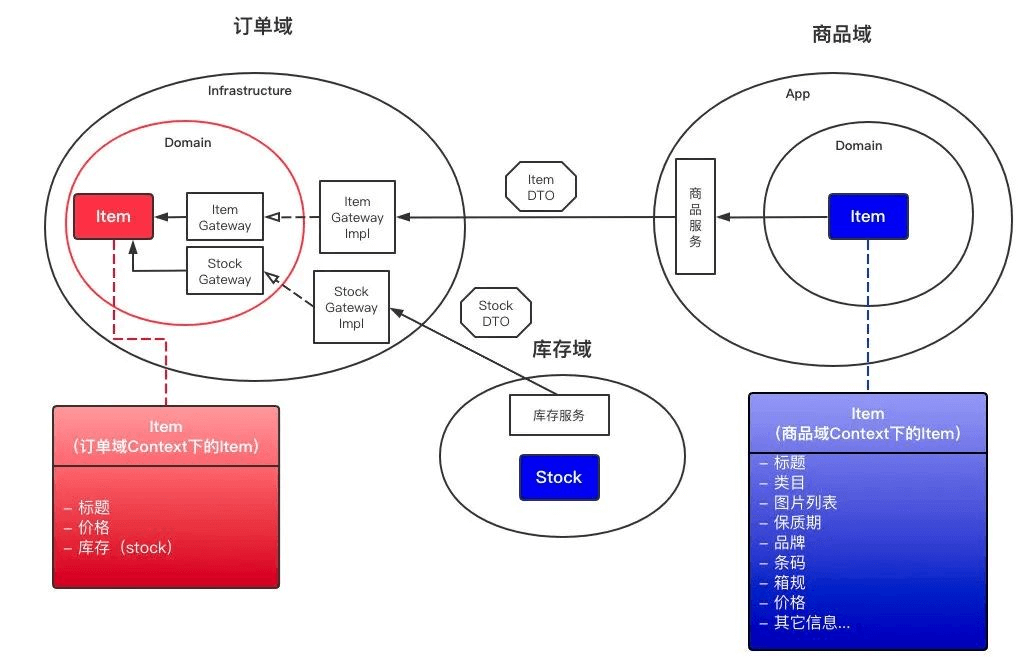
业务域和外部依赖解耦
前面提到的domain和infrastructure层的依赖倒置,是一个非常有用的设计,进一步解耦了取数逻辑的实现。
例如下图中,你的领域实体是商品item,通过gateway接口,你的商品的数据源可以是数据库,也可以是外部的服务API。
如果是外部的商品服务,你经过API调用后,商品域吐出的是一个大而全的DTO(可能包含几十个字段),而在下单这个阶段,订单所需要的可能只是其中几个字段而已。你拿到了外部领域DTO,转为自己领域的Item,只留下标题价格库存等必要的数据字段。
总结
COLA架构并不复杂,COLA已经从1.0版本经过逐次精简,发展到了如今的形态。在阿里云代码脚手架生成器中作为一个可选项,最近的一些新项目已经强制要求使用COLA架构,足见其已经趋于成熟了。

