《Effective Java》笔记
简介
《Effective Java》没什么可说的了,几乎是Java开发者必读书籍。不过在之前读的时候没什么实际经验,很多建议我只是知道要怎么做,但是不明白为什么这么做。现在回过头再次读这本书,发现很多建议我们已经在实践中了,也很好理解为什么要这么做了。

一、创建和销毁对象
1. 用静态工厂方法代替构造器
优点:
1、静态工厂方法可以自定义方法名 拥有更强的可读性。
2、静态工厂方法不必在每次调用它们的时候都创建一个新对象;可以控制类的实例,提升灵活性。
3、静态工厂方法可以返回原返回类型的任何子类型的对象,隐藏构造细节,拥有更好的封装性降低耦合性。
4、静态工厂方法所返回的对象的类可以随着每次调用而发生变化,这取决于静态工厂方法的参数值,提升灵活性。
5、静态工厂方法返回的对象所属的类,在编写包含该静态工厂方法的类时可以不存在,提供了更多的灵活性和可扩展性。
缺点:
1、类如果不含公有的或者受保护的构造器,就不能被子类化。
2、静态工厂方法并不像是构造方法那样在 API 文档中明确标识出来,因此程序员很难发现它们。
2. 遇到多个构造器参数时要考虑使用构建器(Builder模式)
优点:
使用流式构建对象,拥有更强的可读性和可扩展性以及灵活性,可以自由的、链式逐步设置对象的各个属性。
3. 用私有构造器或者枚举类型强化Singleton属性
优点:
1、保证线程安全性。
2、相比于其他方式,如双重检查锁定、静态内部类等代码更简洁。
3、防止反射攻击。
4. 通过私有构造器强化不可实例化的能力
优点:
1、 可以避免被子类实例化避免继承。
2、私有构造器可以阻止类在外部被实例化。
5. 优先考虑依赖注人来引用资源
优点:
1、依赖注入可以减少类之间的依赖关系,使得代码更加松耦合。
2、通过依赖注入,可以更容易地实现组件的重用。
3、 依赖注入可以提高代码的可维护性。
4、依赖注入可以让程序更加灵活,易于扩展和修改。
6. 避免创建不必要的对象
优点:
提高程序性能,避免不必要的资源浪费。
7. 消除过期的对象引用
优点:
消除过期的对象引用可以避免内存泄漏这一严重问题。
8. 避免使用终结方法和清除方法
优点:
终结方法( finalize「)通常是不可预测的,也是很危险的,清除方法没有终结方法那么危险,但仍然是不可预测、运行缓慢,一般情况下也是不必要的 。使用终结方法和清除方法有一个非常严重的性能损失 。 终结方法还有严重的安全问题。
为了避免出现不可预测的问题和性能损失,最好避免使用终结方法和清除方法。
9. try-with-resources优先于 try-finally
优点:
1、try-with-resources提供了一种更简洁的语法来管理资源,更加直观和易于理解。
2、try-with-resources语句可以自动处理资源的关闭,即使在发生异常时也能够正确关闭资源。
二、对于所有对象都通用的方法
1. 覆盖 equals 时请遵守通用约定
原因:
遵守相关约定如自反性、对称性、传递性和一致性等,这样可以减少代码中的错误和混淆。
2. 覆盖 equals 时总要覆盖 hashCode
原因:
没有覆盖hashCode违反了相等的对象必须具有相等的散列码(hash code)。 这可能会导致你在散列数据结构中无法正确地找到对象,或者出现其他不一致的行为。
3. 始终要覆盖 toString
原因:
提供好的toString实现可以便类用起来更加舒适,使用了这个类的系统也更易于调试。
在实际应用中,toString方法应该返回对象中包含的所有值得关注的信息,并且无论是否决定指定格式,都应该在文档中明确地表明你的意图 。
4. 谨慎地覆盖clone
必须确保它不会伤害到原始的对象, 并确保正确地创建被克隆对象中的约束条件。
公有的clone方法应该省略throws声明。
对象拷贝的更好的办法是提供 一 个拷贝构造器(copy constructor)或拷贝工厂(copy factory)。
5. 考虑实现 Comparable 接口
原因:
一旦类实现了Comparable接口,它就可 以跟许多泛型算法(generic algorithm)以及依赖于该接口的集合实现(collection implementation)进行协作。 付出很小的努力就可以获得非常强大的功能。
三、类和接口
1. 使类和成员的可访问性最小化
设计良好的组件会隐藏所有的实现细节, 把 API与实现清晰地隔离开来。
优点:
1、降低耦合度: 封装有助于减少类之间的耦合度,因为其他类只能通过公共接口与对象进行交互,而不是直接访问其内部成员。低耦合度使得代码更易于理解、测试和维护。
2、提高可维护性: 如果内部实现需要更改,只要不改变公共接口,其他代码就不受影响。这种灵活性使得代码更容易维护和扩展。
3、提高安全性: 封装有助于防止非法访问和操纵对象的状态,限制了内部成员的访问。
4、提高易用性:将类的内部实现细节隐藏起来,只向外部暴露必要的接口,用户只需要关注自己关心的API即可快速学习和使用组件。
2. 要在公有类而非公有域中使用访问方法
在设计类的时候应该避免直接暴露类中的成员变量,而是应该通过公有方法来暴露、访问成员变量。
优点:
1、封装实现细节: 将成员变量设为私有,可以隐藏类的内部实现细节,使外部代码不直接依赖于类的具体实现。这提高了代码的封装性,降低了外部对内部实现的依赖性。
2、控制访问权限: 通过提供公有的访问方法,类的设计者可以控制对成员变量的访问权限。可以在公共获取方法中进行权限校验、埋点日志等其他额外操作。
3、灵活性和可维护性: 通过使用访问方法,可以更灵活地修改类的内部实现,而不会影响外部代码。比如以后需要修改成员变量的名称或类型,只需调整公共的访问方法的内部实现,而不会影响到调用者的代码。
3. 复合优先于继承
继承打破了封装性,子类依赖于其超 类中特定功能的实现细节。超类的实现有可能会随着发行版本的不同而有所变化,如果真的发生了变化,子类可能会遭到破坏,即使它的代码完全没有改变 。
优点:
1、更灵活的设计:复合允许你在新的类中包含已有类的对象,而不是直接继承其接口和实现。这样的设计更加灵活,因为你可以根据需要选择组合哪些类,而不受继承链的限制。继承是静态的,一旦继承关系建立,就很难改变。而复合可以在运行时动态地组合对象,可以很灵活的扩展功能。
2、更好的代码复用:复合使得代码复用更加灵活,你可以选择性地使用已有类的功能,而不是强制性地继承整个类的接口和实现。这样可以更精确地控制代码的复用。
4. 要么设计继承并提供文档说明,要么禁止继承
继承很容易被滥用,如果我们真的要设计继承关系,要提供必要的文档,明确说明使用者该如何继承。比如精确地描述覆盖每个方法所带来的影响等。要不就禁止继承,比如使用final修饰。
优点:
1、 明确的设计意图避免滥用继承: 提供文档并明确指导是否允许继承以及如何正确继承的方式,可以帮助其他开发者更好地理解类的设计意图。这有助于避免误用和错误的继承。
2、提高代码可读性和可维护性: 具有清晰文档的类更容易阅读和理解,也更容易维护。
5. 接口优于抽象类
由于Java的单继承限制,使用接口允许类在更灵活的方式下与多个类型进行交互。这种灵活性对于组织和设计复杂的系统非常有帮助,因为它允许类在不同的上下文中扮演不同的角色,而无需受到继承层次结构的限制。因此接口允许构造非层次结构的类型框架,同时接口使得安全地增强类的功能成为可能。
优点:
1、允许构造非层次结构的类型框架:在使用接口时,可以更自由地组织和构建各种类型的框架,而不受传统的类层次结构的限制。
2、安全地增强类的功能:使用接口来扩展和增强类的功能不会影响现有的类结构。
3、 更好的灵活性:由于Java是单继承,因此使用接口可以更灵活的复用多个类的代码同时也不更改类的层级结构。
6. 为后代设计接口
在设计接口时要考虑到未来的扩展和演进,不能仅考虑当前的情况设计出难以扩展的接口。
优点:
1、保持兼容性:即使接口进行了修改或扩展,也要确保现有的实现仍然可以正常工作,以防止破坏现有系统的稳定性。
2、保持扩展性:设计接口时,需要考虑到系统可能面临的未来需求,提供清晰的扩展点。
7. 接口只用于定义类型
接口提供了一种抽象的方式来声明一组方法,而不包含实际的实现。这使得接口成为一种轻量级的、与具体实现无关的类型声明机制。因此不要使用接口去做别的事情,比如用作常量接口是错误的。
8. 类层次优于标签类
标签类职责不单一且没有类层次,使得标签类无法扩展和代码复用。并且由于多个标签实现混在一起,使得代码的可读性和可维护性也非常差。
优点:
1、类层次结构的清晰性: 类层次结构允许你使用继承关系,每个类都有其明确的角色和责任。这样可以更清晰地组织代码,使得每个类都专注于特定的功能,易于理解和维护。
2、可扩展性: 类层次结构更易于扩展。你可以轻松地添加新的子类。
3、代码复用和可维护性:类层次结构有助于代码的重用。在类层次结构中,每个类负责自己的一部分功能,这使得代码更容易维护。
9. 静态成员类优于非静态成员类
优点:
1、独立性: 静态成员类是一个独立的类,与外部类之间的关联更为松散。它不依赖于外部类的实例,因此可以在没有外部类实例的情况下被单独创建和使用。
2、可重用性: 由于静态成员类独立于外部类,它更容易在其他上下文中重用。其他类可以直接实例化静态成员类,而不必先创建外部类的实例。
3、减少内存开销: 静态成员类不持有对外部类实例的引用,这可能减少内存开销,尤其是当静态成员类的实例被大量创建时,同时还能避免内存泄漏问题。
10. 限制源文件为单个顶级类
虽然 Java 编译器允许在一个源文件中定义多个顶级类,但这么做并没有 什么好处,只 会带来巨大的风险 。 因为在一个源文件中定义多个顶级类,可能导致给一个类提供多个定 义 。
优点:
1、避免多个定义冲突: 如果一个源文件包含多个顶级类,并且这些类之间有相互依赖,那么编译器会根据源文件的传递顺序来选择使用哪个定义。这可能导致在不同的编译环境中出现不同的结果,增加了代码的不稳定性。
2、可读性和维护性: 将一个源文件限制为单个顶级类有助于提高代码的可读性和维护性。
3、避免潜在风险:因为Java编译器允许在同一个源文件中定义多个顶级类,而这些类之间可能存在相互依赖或冲突,这可能导致不确定的行为。
四、泛型
1. 请不要使用原生态类型
如果使用原生态类型,就失掉了泛型在安全性和描述性方面的所有优势,Java之所以提供他是为了兼容性。
优点:
1、类型安全性: 泛型提供了编译时类型检查,可以在编译时捕获类型错误,避免在运行时出现异常。
2、代码可读性: 泛型使得代码更加清晰易懂,可以清晰地表达集合中元素的类型,而不需要额外的类型转换或者注释来说明。
3、更好的性能: 泛型可以提供更好的性能,因为它可以避免不必要的类型转换和装箱拆箱操作。
2. 消除非受检的警告
Set<String> exaltation = new HashSet() ;
👇🏻
Set<String> exaltation = new HashSet<>() ;
优点:
1、提高代码质量: 非受检的警告通常表示存在潜在的类型安全问题或者可能的错误。消除这些警告可以提高代码的健壮性和可靠性,减少了在运行时可能出现的异常情况。同时也提高代码的可读性和可维护性
3. 列表优于数组
数组的协变性看似更简单,但实际上泛型的不变性更为安全。
优点:
1、类型安全性: 列表是泛型类型,可以在编译时强制执行类型检查,从而避免因为类型错误导致的运行时异常。与数组相比,列表更加安全。
4. 优先考虑泛型
使用泛型比使用需要在客户端代码中进行转换的类型来得更加安全,也更加容易 。 在设计新类型的时候,要确保它们不需要这种转换就可以使用 。 这通常意味着要把类做成是泛型的 。 只要时间允许,就把现有的类型都泛型化 。 这对于这些类型的新用户来说会变得更加轻松,又不会破坏现有的客户端。
优点:
1、泛型比类型转换更安全、更容易: 使用泛型可以避免在客户端代码中进行类型转换,这样可以减少因为类型转换而引入的潜在错误。同时,泛型也使得客户端代码更加清晰易读。
5. 优先考虑泛型方法
泛型方法就像泛型一样,使用起来比要求客户端转换输入参数并返回值的方法来得更加安全,也更加容易。 就像类型一样,你应该确保方法不用转换就能使用 ,这通常意味着要将它们泛型化。并且就像类型一样,还应该将现有的方法泛型化,使新用户使用起来更加轻松 ,且不会破坏现有的客户端。
优点:
1、通用性: 泛型方法可以处理各种类型的数据,而不需要为每种类型都编写一个具体的方法。这使得代码更具通用性,可以在多种场景下重复使用。
2、类型安全性: 泛型方法在编译时可以进行类型检查,可以确保方法在调用时传递的参数类型是正确的,从而避免了因为类型错误而导致的运行时异常。
3、简洁性: 使用泛型方法可以减少代码的重复量,因为不需要为每种类型都编写一个单独的方法。这使得代码更加简洁易读,减少了代码的冗余。
4、灵活性: 泛型方法可以适用于多种数据类型,使得代码更加灵活。这意味着可以更轻松地对方法进行扩展和修改,而不会受到特定类型的限制。
5、代码清晰度: 使用泛型方法可以使得代码更加清晰易懂,因为它们表达了方法对于参数类型的泛化处理,而不需要额外的类型转换或者注释来说明。
6. 利用有限制通配符来提升 API 的灵活性
为了获得最大限度的灵活性,要在表示生产者或者消费者的输入参数上使用通配符类型 。
例如:
Comparable<? super b> 优先于 Cornparable<T>
优点:
1、兼容性: 有限制通配符允许方法接受参数的范围更广,这提高了方法的兼容性,从而增强了 API 的通用性。
2、灵活性: 使用有限制通配符可以允许客户端代码传递具有不同上限限制的类型。这使得客户端代码更加灵活。
3、安全性: 有限制通配符保留了参数类型的部分信息,即参数类型必须是指定的类型或其子类型。这有可以确保方法在运行时处理的对象符合类型要求,从而提高了代码的安全性避免了运行期间的异常。
7. 谨慎并用泛型和可变参数
当可变参数有泛型或者参数化类型时,编译警告信息就会产生混乱。
优点:
1、安全性:将值保存在泛型可变参数数组参数中是不安全的,允许另一个方法访问一个泛型可变参数数组也是不安全的。
五、枚举和注解
1. 用enum代替int常量
枚举的可读性更好, 也更加安全,功能更加强大 。 许多枚举都不需要显式的构造器或者成员,但许多其他枚举则受益于属性与每个常量的关联以及其行为受该属性影响的方法。只有极少数的枚举受益于将多种行为与单个方法关联 。在这种相对少见的情况下,特定于常量的方法要优先于启用自有值的枚举。 如果多个(但非所有)枚举常量同时共享相同的行为,则要考虑策略枚举。
优点:
1、可读性好:使用实例域可以为每个枚举常量提供一个描述性的名称,这使得代码更易于理解和维护。
2、可扩展性好:使用实例域可以更灵活地表示枚举常量的属性和状态。通过为每个常量定义独立的实例域,可以更容易地在将来添加新的属性或修改现有属性,而不需要修改依赖该枚举的其他代码。
3、安全性好:使用实例域可以提高类型安全性,因为实例域的类型是明确的,而不是简单的整数值。这可以避免因为序数值被错误地用于其他目的而导致的潜在错误。
4、更具意义的比较: 使用实例域可以进行更具意义的比较,而不是仅仅比较序数值。这可以使代码更加直观,并且可以避免因为枚举常量顺序的改变而引起的问题。
2. 用EnumSet代替位域
public enum Color {
RED, GREEN, BLUE;
}
public class Colors {
public static final int RED = 1 << 0;
public static final int GREEN = 1 << 1;
public static final int BLUE = 1 << 2;
}
位域:
int colors = Colors.RED | Colors.GREEN; // 表示红色和绿色的组合
使用EnumSet代替位域:
import java.util.EnumSet;
public class Main {
public static void main(String[] args) {
EnumSet<Color> colors = EnumSet.of(Color.RED, Color.GREEN);
// 表示红色和绿色的组合
System.out.println(colors);
}
}
优点:
1、安全性:EnumSet是类型安全的,它只能包含特定枚举类型的值。这可以避免运行时异常。
2、可读性:EnumSet提供了更具可读性的API,可以更清晰地表示枚举类型的组合。
3、灵活性:EnumSet提供了丰富的集合操作方法,如并集、交集、差集等,使得对枚举值的组合更加灵活和方便。而且,它支持泛型,可以适用于不同的枚举类型。
4、性能:EnumSet在内部使用位向量(bit vector)来表示枚举值的集合,因此它具有很高的性能,尤其在需要进行集合运算时,比手动位操作更高效。
5、线程安全性:EnumSet是线程安全的,可以在多线程环境中安全使用。
3. 用EnumMap代替序数索引
意义同上(使用EnumSet代替位域)。
优点:
1、安全性:EnumMap是类型安全的,它只能包含特定枚举类型的键值对。这可以避免运行时异常。
2、可读性:EnumMap提供了更具可读性的 API,可以更清晰地表示枚举类型与值之间的映射关系。
3、灵活性:EnumMap提供了丰富的Map操作方法,如添加、删除、遍历等,使得对枚举类型与值的映射关系更加灵活和方便。而且,它支持泛型,可以适用于不同的枚举类型。
4、性能:EnumMap在内部使用数组来表示键值对,因此它具有很高的性能。而且,由于枚举类型的数量通常有限且固定,因此 EnumMap 的性能表现稳定且可预测。
5、线程安全性:EnumMap是线程安全的,可以在多线程环境中安全使用。
4. 用接口模拟可扩展的枚举
虽然无法编写可扩展的枚举类型,却可以通过编写接口以及实现该接口的基础枚举类型来对它进行模拟。这样允许客户端编写自己的枚举(或者其他类型)来实现接口。如果 API 是根据接口编写的,那么在可以使用基础枚举类型的任何地方,也都可以使用这些枚举。
优点:
1、灵活性和扩展性: 接口模拟可扩展的枚举使得枚举值的扩展更加灵活。通过定义接口,并让枚举类实现该接口,可以在不修改原有枚举类的情况下添加新的枚举值。
可读性: 接口可以提供更加具有描述性的方法名和属性,使得代码更易于理解和维护。相比之下,传统的枚举通常只能使用常量值,代码可读性不如接口。
5. 注解优先于命名模式
有了注解,就完全没有理由再使用命名模式了。
优点:
1、可读性: 注解提供了更清晰的语义,可以直观地描述某个元素的特性或者用途。相比之下,命名模式可能会导致名称过长或者不够清晰,使得代码难以理解,并且命名可能因为拼写错误而导致问题。
2、灵活性: 注解可以带有参数,使得配置更加灵活。通过为注解添加参数,可以轻松地调整元素的行为或属性,而不需要修改命名模式中的名称。
4、维护性: 使用注解可以将元数据与代码逻辑分离开来,使得代码更易于维护。通过在注解中定义元数据,可以更容易地对代码进行修改或者调整,而不会影响到代码逻辑。
5、扩展性: 注解提供了一种标准化的方式来描述元素的特性,使得代码更易于扩展。通过定义自定义注解,可以根据需要添加新的特性或者扩展现有的特性,而不需要修改命名模式中的名称。
6. 坚持使用Override注解
如果在你想要的每个方法声明中使用Override注解来覆盖超类声明,编译器就可以替你防止大量的错误。
优点:
1、安全性: 使用@Override注解可以告诉编译器,你打算覆盖(重写)父类中的方法。如果方法名拼写错误、参数类型不匹配或者方法签名不正确,编译器将会产生错误提示,提醒你可能存在的错误。
2、可读性:@Override注解提供了一种清晰的方式来表示某个方法是重写父类中的方法。这样做可以让代码更易于理解,也可以帮助其他开发人员更快地理解你的代码意图。
7. 用标记接口定义类型
标记接口和标记注解都各有用处。如果想要定义一个任何新方法都不会与之关联的类型,标记接口就是最好的选择。如果想要标记程序元素而非类和接口,或者标记要适合于已经广泛使用了注解类型的框架,那么标记注解就是正确的选择。
比如Java 中的
Serializable接口就是一个标记接口。
优点:
1、可读性:标记接口可以增强代码的可读性。通过查看类是否实现了特定的标记接口,可以直观地了解其具有的特性或行为,从而使得代码更易于理解和维护。
2、安全性:标记接口可以提供一种类型安全的方式来标记类。只有实现了标记接口的类才会具有相应的行为或特性,从而在编译时可以捕获到类型错误。
3、灵活性:标记接口提供了一种灵活的方式来扩展类的行为。通过为类添加或移除标记接口,可以动态地调整其行为或特性,而不需要修改类的实现代码。
六、Lambda和Stream
1. Lambda优先于匿名类
Lambda优先于匿名类的最大原因是代码更简洁,但是Lambda是匿名的,如果在Lambda中写过多的逻辑会降低代码可读性和可维护性。
优点:
1、简洁性:Lambda表达式可以显著地减少代码的量。相比于使用匿名类,Lambda表达式更为简洁。
2. 方法引用优先于Lambda
// 使用Lambda表达式
strings.forEach(s -> System.out.println(s));
// 使用方法引用
strings.forEach(System.out::println);
优点:
1、简洁性:只要方法引用更加简洁、清晰,就用方法引用;如果方法引用并不简洁,就坚持使用Lambda。
3. 坚持使用标准的函数接口
java. util.function包已经提供了大量标准的函数接口。只要标准的函数接口能够满足需求,通常应该优先考虑,而不是专门再构建一个新的函数接口 。
千万不要用带包装类型的基础函数接:使用装箱基本类型进行批量操作处理,最终会导致致命的性能问题。
必须始终用@Functionallnterface注解对自己编写的函数接口进行标注。
优点:
1、代码可读性: 标准的函数接口提供了对特定功能的清晰抽象,使得代码更易读、易理解。使用标准的函数接口可以让其他开发者迅速理解你的代码意图,降低了代码的认知负担。
4. 谨慎使用Stream
原因:
1、性能考虑: 虽然Stream提供了方便的函数式编程方式来操作集合,但它们可能不是最高效的方式。在某些情况下,使用传统的循环方式可能会更快,特别是在处理大数据量或性能敏感的场景下。Stream的操作可能涉及到自动装箱、拆箱和迭代器的使用,这些操作都可能引入额外的性能开销。
2、难以调试: Stream操作通常是链式调用的方式,这使得代码更为简洁,但也增加了调试的难度。当Stream链中的某个操作出现问题时,跟踪问题并定位bug可能会比传统的循环方式更加困难,特别是对于复杂的操作链。
3、难以理解: 虽然Stream提供了函数式编程的方式来处理集合,但是滥用Stream会使代码更难以读懂和维护。
4、内存消耗: Stream的操作通常会创建一系列中间结果对象,这些对象可能会占用大量的内存,尤其是在链式调用中存在多个中间操作的情况下。如果处理的数据量很大,可能会导致内存消耗过高的问题。
5、并发安全性: 在并行Stream操作中,需要特别注意并发安全性的问题。虽然Stream提供了并行操作的便利性,但在某些情况下可能会出现竞态条件或不确定的行为,需要谨慎处理并发情况下的数据共享和修改。
5. 优先选择Stream中无副作用的函数
副作用是指函数除了返回值之外,还会对外部状态产生影响的行为。比如传入一个subOrders数组,函数的作用是计算出总金额,正确的应该是只在函数中累计金额,如果在函数中还做了其他改变外部状态的行为,比如说在函数中还根据订单的价格设置了subOrders数组元素的是否是0元子订单的操作。这就是产生了副作用。
优点:
1、可读性: 无副作用的函数更容易理解,因为它们不会对外部状态产生影响,只关注输入和输出之间的关系。
2、可维护性: 无副作用的函数更易于维护,因为它们不会隐藏任何隐式的状态变化,可以更清晰地理解函数的行为。
3、并发安全性: 无副作用的函数更容易进行并发编程,因为它们不会修改共享的状态,减少了并发竞争的可能性。
4、可测试性: 无副作用的函数更容易进行单元测试,因为测试过程中不需要关心函数对外部状态的影响,只需要验证输入和输出之间的关系即可。
6. Stream要优先用Collection作为返回类型
原因:
1、兼容性: 有些用户可能想要当作 Stream处 理,而其他用户可能想要使用迭代。 要尽量两边兼顾。
7. 谨慎使用Stream并行
并行Stream不仅可能降低性能,包括活性失败,还可能导致结果出错,以及难以预计的行为。
原因:
1、性能问题: 在某些情况下,并行 Stream 可能导致性能下降,而不是提升。并行 Stream 操作涉及到线程的创建、销毁和调度等额外开销,以及线程之间的通信和同步开销。如果数据量较小或者处理时间较短,这些额外开销可能会超过并行执行所带来的性能提升,从而导致性能下降。此外,并行执行也可能会导致额外的竞争和争用资源,如内存、锁、IO等,进一步影响性能。
2、正确性问题: 并行 Stream 操作可能会破坏原有的数据依赖性,导致结果的正确性出现问题。例如,在对数据进行排序或者去重的操作中,并行执行的顺序是不确定的,这可能导致最终结果的顺序出现问题。此外,并行操作还可能出现竞态条件等问题,例如在操作共享变量时可能会出现线程安全问题。因此,在进行并行操作时,需要确保操作之间没有数据依赖性,或者采取合适的同步措施来保证操作的正确性。
七、方法
1. 检查参数的有效性
优点:
1、提高代码的健壮性: 参数有效性检查可以防止无效或不合法的参数被传递给方法,从而减少了出错的可能性。通过在方法的开头进行参数有效性检查,可以在程序执行过程中尽早发现问题,并及时进行处理,从而提高了代码的健壮性和稳定性。
2、提高代码的可读性: 在方法的开头对参数进行有效性检查,可以使得代码更易读、更易理解。有效性检查清晰地表达了方法的前置条件,让其他开发者更容易理解方法的预期行为,并正确地使用该方法。
3、提高代码的可维护性: 有效性检查使得方法更加自包含(self-contained),即方法内部对输入参数的合法性进行了检查,不需要依赖外部调用者来保证参数的有效性。这样一来,当方法内部逻辑发生变化时,不需要修改调用者的代码,从而提高了代码的可维护性。
4、提高用户体验: 如果方法能够及时地对输入参数的有效性进行检查,并给出明确的错误提示,可以帮助用户更快地发现和解决问题,提高用户的体验和满意度。
2. 必要时进行保护性拷贝
保护性拷贝:用于保护对象的数据不受外部修改的影响。在进行保护性拷贝时,通常会创建对象的一个副本(拷贝),然后将该副本提供给外部使用,而不是直接暴露原始对象。这样可以确保外部修改对原始对象数据不会产生影响。
优点:
1、防止外部修改对原始数据的影响: 通过进行保护性拷贝,可以防止外部对拷贝后的数据进行修改对原始数据造成影响。这在多线程环境下尤为重要,因为多个线程可能同时访问相同的数据,如果没有进行保护性拷贝,就可能导致数据的不一致性和并发安全问题。
2、提高代码的健壮性和可靠性: 通过进行保护性拷贝,可以减少外部对数据的直接修改,降低程序出错的可能性,从而提高代码的健壮性和可靠性。此外,保护性拷贝还可以减少数据不一致性和错误的发生,提高程序的稳定性。
3. 谨慎设计方法签名
原因:
1、可读性:见名知意的方法名可以提高代码的可读性。
2、可维护性:避免过长的参数列表。
3、可扩展性:对于参数类型,要优先使用接口而不是类。
4. 慎用重载
要调用哪个重载方法是在编译时做出决定的。对于重载方法的选择是静态的,而对于被覆盖的方法的选择则是动态的。永远不要导出两个具有相同参数数目的重载方法。始终可以给方法起不同的名称,而不使用重载机制。
不要在相同的参数位置调用带有不同函数接口的方法。
原因:
1、混淆: 过度使用方法重载可能会导致代码混乱,降低代码的可读性和可理解性。当存在多个重载版本的方法时,使用者可能会难以确定应该调用哪个版本,容易造成误解和错误。
2、隐藏行为: 如果方法重载的参数类型和数量差别不大,容易造成方法的行为隐藏。这意味着同一个方法名称可能具有不同的行为,这会让使用者感到困惑,增加了出错的可能性。
3、增加维护成本: 当需求发生变化时,过多的方法重载可能会增加维护成本。每次修改方法时,都需要考虑多个重载版本的影响,增加了代码维护的复杂性。
5. 慎用可变参数
原因:
1、可读性差: 可变参数使得方法的调用者可以传递任意数量的参数,这增加了方法的灵活性,但也降低了代码的可读性。调用者可能传入不同数量的参数,导致方法的行为不确定,增加了代码的理解和维护难度。
2、性能问题: 使用可变参数可能会导致性能问题。可变参数在编译时会被转换成数组,而数组的创建和初始化需要额外的时间和内存开销。如果方法频繁被调用,这些额外开销可能会对性能产生影响。
6. 返回零长度的数组或者集合,而不是null
原因:
1、避免空指针异常: 返回null可能会导致调用者在使用返回值时出现空指针异常。通过返回一个零长度的数组或者集合,可以避免这种情况的发生,使得调用者不需要在使用返回值前进行额外的null检查。
2、提高代码的健壮性: 返回零长度的数组或者集合可以提高代码的健壮性,使得方法在各种情况下都能够正常工作。因为调用者无论收到什么样的返回值,都可以对其进行安全的操作,而不会出现空指针异常或其他不可预料的情况。
7. 谨慎返回optinal
如果无法返回结果并且当没有返回结果时客户端必须执行特殊的处理,那么就应该声明该方法返回Optional<T>
原因:
1、引入额外复杂性: 返回 Optional 可能会引入额外的复杂性,因为调用者需要处理 Optional 对象的包装。这增加了代码的复杂性和理解难度,特别是对于不熟悉 Optional 的开发者来说。
2、不必要的包装: 返回 Optional 可能会导致不必要的包装,增加了内存和性能开销。Optional 是一个包装类,它需要额外的对象来存储被包装的值,这可能会导致内存占用和对象创建的增加。
8. 为所有导出的 API 元素编写文档注释
为了正确地编写 API 文档,必须在每个被导出的类、接口、构造器、方法和域声明之前增加一个文档注释。
方法的文档注释应该简洁地描述出它和客户端之间的约定。
文档注释在源代码和产生的文档中都应该是易于阅读的。
同一个类或者接口中的两个成员或者构造器,不应该具有同样的概要描述。
当为泛型或者方法编写文档时,确保要在文档中说明所有的类型参数。
为注解类型编写文档时,要确保在文档中说明所有成员。
类或者静态方法是否线程安全,应该在文档中对它的线程安全级别进行说明。
优点:
1、提高代码可读性: 文档注释提供了对 API 元素功能和用法的清晰描述,使得其他开发者能够快速理解和正确使用代码,从而提高了代码的可读性,降低了理解成本。
八、通用编程
1. 将局部变量的作用域最小化
要使局部变量的作用域最小化 ,最有力的方法就是在第一次要使用它的地方进行声明。
// 使用不同的迭代器变量来遍历不同的集合
Iterator<Integer> i = c1.iterator();
while (i.hasNext()) {
doSomething(i.next());
}
Iterator<Integer> i2 = c2.iterator();
// 代码不报错但是逻辑错误!使用fori/forin就不会有这样的问题 因为他们的变量作用域仅限于循环内部
while (i.hasNext()) {
doSomethingElse(i.next());
}
把局部变量的作用域最小化避免潜在的Bug,因为随着代码的迭代越来越复杂,可能会用错变量导致一系列问题。
JavaScript在最初使用
var来申明变量,但是var声明出来的变量是全局变量,在ES6规范后推荐使用let(块级作用域)来申明局部变量。这个规范也遵循了这一原则。
2. for-each循环优先于传统的for循环
for (MyItem item : items) {
System.out.println(item);
}
for-each也称为增强for循环,代码会更简洁,但是并不是完全适用全部场景。如果因为我们关注的是遍历出来的每一个元素本身,并不关注索引或是对原始列表操作(比如遍历过程中删除列表的元素)推荐使用增强for。
3. 了解和使用类库
String url = "https://www.lazada.com";
try {
// 创建 URL 对象
URL obj = new URL(url);
// 打开连接
HttpURLConnection con = (HttpURLConnection) obj.openConnection();
// 设置请求方法为 GET
con.setRequestMethod("GET");
// 获取响应代码
int responseCode = con.getResponseCode();
System.out.println("Response Code: " + responseCode);
// 读取响应内容
BufferedReader in = new BufferedReader(new InputStreamReader(con.getInputStream()));
String inputLine;
StringBuilder response = new StringBuilder();
while ((inputLine = in.readLine()) != null) {
response.append(inputLine);
}
in.close();
// 打印响应内容
System.out.println("Response Body:\n" + response.toString());
} catch (IOException e) {
e.printStackTrace();
}
String url = "https://www.lazada.com";
// 发起 GET 请求并获取响应内容
String response = HttpUtil.get(url);
// 打印响应内容
System.out.println("Response Body:\n" + response);
Java的生态已经十分完整了,很多需求应该先去找找有没有已经实现的类库。如果已经有了就没必要重复造轮子了。而且很多类库都是开源的,代码经过很多版本的迭代和实际验证,大多数情况下类库的质量优于自己实现。
4. 如果需要精确的答案,请避免使用float和double
float和double类型没有提供完全精确的结果,因此不适合用于精确计算,比如货币计算。
如果数值范围没有超过9位十进制数字,就可以使用int;如果不超过18位数字,就可以使用long。
如果数值可能超过18位数字,就必须使用BigDecimal。
5. 基本类型优先于装箱基本类型
原因:
- 包装类型在自动装箱、拆箱过程中有性能损耗,并且可能会产生不必要的对象。如果这出现在循环代码中对性能影响会更严重。
public static void main(String[] args) {
Long start = System.currentTimeMillis();
Long sum = 0L;
for (Long i = 0L; i < 1000000L; i++) {
sum += i;
}
Long end = System.currentTimeMillis();
System.out.println("使用Long耗时: " + (end - start) + " 毫秒");
Long start2 = System.currentTimeMillis();
long sum2 = 0L;
for (long i = 0; i < 1000000; i++) {
sum2 += i;
}
Long end2 = System.currentTimeMillis();
System.out.println("使用long耗时: " + (end2 - start2) + " 毫秒");
}
- 包装类型某些时候会自动拆箱(比如和基本类型混用的时候),如果一个null值被自动拆箱就会报错。
public static void main(String[] args) {
Integer a = null;
int b = 0;
// 自动拆箱会导致 NullPointerException 错误
int c = a - b;
System.out.println(c);
}
- 包装类型的本质是对象,所以在做一些对比操作的时候要格外注意,比如使用
==来对比两个包装类型会导致预期外的结果,有时即使他们的值看起来一样但是会返回false。
public static void main(String[] args) {
Integer a = 9999;
Integer b = 9999;
System.out.println(a == b);
}
6. 如果其他类型更适合,则尽量避免使用字符串
使用字符串来代替其他类型会降低代码的可读性,其次字符串代替对象会损失Java的类型检查优势,同时Java的String是不可变的每次操作String的性能也不好。
类型检查是强类型语言的重要优势之一,能帮我们在编译期间就发现问题,避免潜在Bug。TypeScript的兴起正是因为JavaScript不支持类型检查,因此十分不推荐使用字符串来替代对象。
假设使用字符串(json格式)来替代对象:
{
"orderId": "12000000999",
"amount": {
"cent": 1,
"currency": "PHP"
}
...
}
如果有不遵守约定的行为,比如amount可以直接传递一个数值:
这样在后续的处理代码中就会导致出错,但是编译期间无法发现。
{
"orderId": "12000000999",
"amount": 1
...
}
使用字符串的好处也是显而易见的,更灵活通用。
7. 了解字符串连接的性能
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
/**
* The value is used for character storage.
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*
* Additionally, it is marked with {@link Stable} to trust the contents
* of the array. No other facility in JDK provides this functionality (yet).
* {@link Stable} is safe here, because value is never null.
*/
@Stable
private final byte[] value;
String的内部是一个不可变的字节数组,操作String会出现数组拷贝的情况,如果大量拼接字符串会导致大量的数组拷贝产生大量垃圾对象,对性能影响很大,推荐使用StringBuilder的append方法。而不是+。
public static void main(String[] args) {
String str = "";
Long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
str += i;
}
Long end = System.currentTimeMillis();
System.out.println("String + 耗时:" + (end - start) + "毫秒");
StringBuilder sb = new StringBuilder();
Long start2 = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
sb.append(i);
}
Long end2 = System.currentTimeMillis();
System.out.println("StringBuilder append 耗时:" + (end2 - start2) + "毫秒");
}
8. 通过接口引用对象
使用接口引用对象能使得我们的程序更加灵活(Java的多态性),我们可以无缝切换到接口的其他实现。同时使用接口而不是具体的类也有助于解耦。我们现在都是这么用的。
// 只是做演示 一般我们会用框架IoC容器来自动注入从而做到解耦
PaymentService service = new PaymentServiceImpl();
9. 接口优先于反射机制
如果你编写的程序必须要与编译时未知的类一起工作,如有可能,就应该仅仅使用反射机制来实例化对象,而访问对象时则使用编译时已知的某个接口或者超类。
接口可以使用到Java的类型检查优势,避免出错。如果使用纯反射调用,即便是调用一个本不存在的方法也会不会在编译期间显示出来。而且反射代码非常笨拙和冗长。另外反射代码的性能十分低。
假设我们有一个程序,需要在运行期间动态支持一些插件的加入。
使用反射来调用:
// 插件类名
String pluginClassName = getPluginClassNameFromConfig();
// 获取类对象
Class<?> clazz = Class.forName(pluginClassName);
// 实例化对象
Object obj = clazz.newInstance();
// 获取方法对象 这里把方法名写错了 execute写成了executet 编译期间不会报错
Method method = clazz.getMethod("executet", String.class);
// 调用方法
method.invoke(obj, "/blogs/file/style.js");
使用反射+接口:
// 插件类名
String pluginClassName = getPluginClassNameFromConfig();
// 仅使用反射机制实例化插件对象
Class<?> pluginClass = Class.forName(pluginClassName);
// 使用MyPlugin接口来做类型检查
MyPlugin plugin = (MyPlugin) pluginClass.newInstance();
// 调用插件的方法
plugin.execute("/blogs/file/style.js");
性能影响:
反射调用
MyClass myClass = new MyClass();
long startTime = System.nanoTime();
Method method = MyClass.class.getMethod("printMessage", String.class);
method.invoke(myClass, "打印");
long endTime = System.nanoTime();
long time = endTime - startTime;
System.out.println("耗时: " + time + "纳秒");
普通调用
MyClass myClass = new MyClass();
long startTime = System.nanoTime();
myClass.printMessage("打印");
long endTime = System.nanoTime();
long time = endTime - startTime;
System.out.println("耗时: " + time + "纳秒");
10. 谨慎地使用本地方法
本地方法是指用本地编程语言(比如C或者C++)来编写的方法 。 它们提供了“访问特定于平台的机制”的能力,比如访问注册表(registry)。
使用本地方法会导致程序依赖本地环境,比如程序使用访问注册表的本地方法在注册表存储内容,由于注册表是Windows平台特有的如果将程序部署在MacOS/Linux上就会报错。JVM的最大特性就是屏蔽底层差异,实现跨平台,所以要尽可能少的直接调用底层方法,另外现在的JVM已经很成熟了,几乎不需要使用本地方法来优化性能了。
11. 谨慎地进行性能优化
要努力编写好的程序而不是快的程序。
试图做的优化通常对于性能并没有明显的影响,有时候甚至会使性能变得更差。
编写好的程序,好的性能也会随之而来。如果对性能不满意再做剖析找到根本原因在做优化,不要盲目优化。
例如在拼接字符串的时候,仅有三个字符串相连,使用+使得代码简洁同时性能也很好。如果非要优化为StringBuilder反而导致增加了创建StringBuilder对象的成本,代码也变得更冗长。
12. 遵守普遍接受的命名惯例
遵守普遍接受的命名惯例能代码的可读性和可维护性变得更好。
九、异常
1. 只针对异常的情况才使用异常
异常应该只用于异常的情况下;它们永远不应该用于正常的控制流。
异常处理的性能很低,不应该用于控制流。如果不是在异常情况使用异常可能会吃掉某些代码的异常,从而导致Bug,增加了调试和发现问题的成本。
2. 对可恢复的情况使用受检异常,对编程错误使用运行时异常
受检异常:在编译时必须进行处理的异常,即编译器会强制要求程序员在程序中显式地处理或者声明抛出这类异常。比如在使用反射调用的时候会要求必须处理受检异常ClassNotFoundException
受检异常可以向上传递。
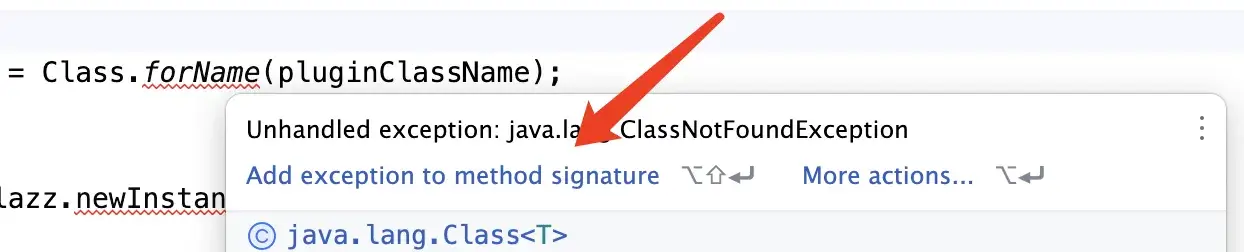
运行时异常:指在程序运行时可能会抛出的异常。比如常见的NullPointerException
行时异常一般都是RuntimeException的子类。
如果期望调用者能够适当地恢复,对于这种情况就应该使用受检异常。编程错误使用运行时异常。
受检异常一般提供了恢复条件,比如IO操作遇到文件不存在,可以通过捕获异常后做恢复,创建一个文件。
运行时异常通常用于表示程序中的编程错误,这些错误通常是由程序员的逻辑错误或者不正确的使用方式引起的,比如调用者传递了个null值参数,这是不可预料的。程序也无法处理此类错误。
3. 避免不必要地使用受检异常
受检异常可以提升程序的可读性,还能强迫调用者处理异常。但是如果调用者无法恢复失败,就应该抛出未受检异常。如果抛出一个不可恢复的受检异常会让API变得难用。
下面这个方法抛出了一个不可恢复的受检异常,数据库连接失败,是无法恢复的异常,应该抛出运行时异常。
public static Connection getConnection() throws SQLException {
return DriverManager.getConnection(URL, USER, PASSWORD);
}
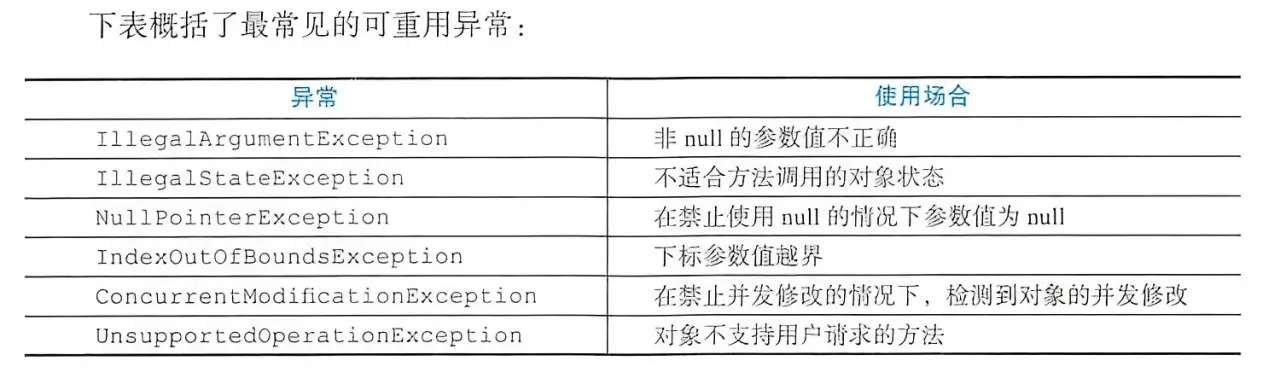
4. 优先使用标准的异常
使用标准的异常能提高代码复用,降低使用和学习门槛,使用标准异常而非自定义异常也能降低内存占用(装载自定义异常)。但是不应该直接复用Exception、RuntimeException、Throwable或者Error。这些异常太过于宽泛,不利于定位问题,应该使用具体的异常。
5. 抛出与抽象对应的异常
如果方法抛出的异常与它所执行的任务没有明显的联系,这种情形将会使人不知所措 。 当方法传递由低层抽象抛出的异常时,往往会发生这种情况 。 除了使人感到困惑之外,这也 “污染”了具有实现细节的更高层的 API。 如果高层的实现在后续的发行版本中发生了变化, 它所抛出的异常也可能会跟着发生变化,从而潜在地破坏现有的客户端程序。
为了避免这个问题,更高层的实现应该捕获低层的异常,同时抛出可以按照高层抽象 进行解释的异常。
这种做法称为异常转译( exception translation)。
处理来自低层异常的最好做法是,在调用低层方法之前确保它们会成功执行,从而避免它们抛出异常。有时候,可以在给低层传递参数之前,检查更高层方法的参数的有效 性,从而避免低层方法抛出异常。
举例来说我们提供一个支付接口,然后我们抛出了一个空指针异常。调用者无法得知我们的内部逻辑,无法解释异常。我们应该进行一些必要的校验和捕获,比如空指针的原因是订单发起支付的用户id不存在,我们应该转换为我们的支付异常,并返回标准的错误码和错误原因,方便用户理解异常。
6. 每个方法抛出的所有异常都要建立文档
描述一个方法所抛出的异常,是正确使用这个方法时所需文档的重要组成部分。 因此,花点时间仔细地为每个方法抛出的异常建立文档是特别重要的。
始终要单独地声明受检异常, 并且利用Javadoc的@Throws标签, 准确地记录下抛出每个异常的条件。
如果没有为可以抛出的异常建立文档,其他人就很难或者根本不可能有效地使用你的类和接口。
7. 在细节消息中包含失败 一 捕获信息
为了捕获失败,异常的细节信息应该包含“对该异常有贡献”的所有参数和域的值。
但是千万不要在细节消息中包含密码、密钥以及类似的信息!
也就是说,在抛出异常的时候异常信息应该包含该方法的入参以及一些其他依赖的属性值。这样才能定位问题所在。
8. 努力使失败保持原子性
当对象抛出异常之后,通常我们期望这个对象仍然保持在一种定义良好的可用状态之中,即使失败是发生在执行某个操作的过程中间。对于受检异常而言,这尤为重要,因为调用者期望能从这种异常中进行恢复。 一般而言,失败的方法调用应该使对象保持在被调用之前的状态 。 具有这种属性的方法被称为具有失败原子性。
方法产生的任何异常都应该让对象保持在调用该方法之前的状态。
例如,假设有一个银行账户对象,其中包含一个方法用于执行转账操作。如果在执行转账操作的过程中发生异常,账户对象应该能够保持在转账之前的状态,以避免账户余额出现不一致的情况。这样的方法就具有了失败原子性。
10. 不要忽略异常
空的catch块会使异常达不到应有的目的!
如果真的需要忽略异常,catch块中应该包含一条注释,说明为什么可以这么做,并且变量应该命名为 ignored。
try {
test();
} catch (Exception ignored) {
// 仅用于测试所以忽略异常
}
忽略异常会使程序出一些奇怪的Bug,由于异常被吞掉,很难发现问题的原因。异常就像是火警信号器,忽略异常就像是关闭火警信号器一样,如果把火警信号器关掉了,当真正有火灾发生时,就没有人能看到火警信号了。 结果将是灾难性的。
十、并发
1. 同步访问共享的可变数据
为了提高性能,在读或写原子数据的时候,应该避免使用同步?这个建议是非常危险而错误的。 虽然语言规范保证了线程在读取原子数据的时候,不会看到任意的数值,但是它并不保证一个线程写人的值对于另一个线程将是可见的。为了在线程之间进行可靠的通信,也为了互斥访问,同步是必要的。
将可变数据限制在单个线程中。
当多个线程共享可变数据的时候,每个读或者写数据的线程都必须执行同步。如果没有同步,就无法保证一个线程所做的修改可以被另一个线程获知。
未能同步共享可变数据会造成程序的活性失败和安全性失败。
public class Counter {
private int count = 0;
// 使用同步方法来增加计数器的值
public synchronized void increment() {
count++;
}
// 使用同步方法来获取计数器的值
public synchronized int getCount() {
return count;
}
public static void main(String[] args) {
Counter counter = new Counter();
// 创建多个线程,每个线程执行多次增加操作
Runnable task = () -> {
for (int i = 0; i < 1000; i++) {
counter.increment();
}
};
Thread thread1 = new Thread(task);
Thread thread2 = new Thread(task);
// 启动线程
thread1.start();
thread2.start();
try {
// 等待两个线程执行完成
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 打印最终的计数器值
System.out.println("Final count: " + counter.getCount());
}
}
活性失败:活性指的是程序在执行过程中能够继续前进,不会陷入死锁、饥饿或活锁等状态。活性失败指的是程序处于某些原因无法继续执行,比如死锁。
安全性失败:安全性是说多线程程序在执行的时候不会破坏共享数据和竞态条件。安全性失败是说多线程运行的时候没有正确的进行同步,破坏了共享数据等原因导致程序出错。
2. 避免过度同步
为了避免活性失败和安全性失败,在一个被同步的方法或者代码块中,永远不要放弃对客户端的控制。
在一个被同步的区域内部,不要调用设计成要被覆盖的方法,或者是由客户端以函数对象的形式提供的方法。 从包含该同步区域的类的角度来看,这样的方法是外来的。这个类不知道该方法会做什么事情,也无法控制它。根据外来方法的作用,从同步区域中调用它会导致异常、死锁或者数据损坏。
为了避免死锁和数据破坏,千万不要从同步区域内部调用外来方法,同时应该在同步区域内做尽可能少的工作。如果你必须要执行某个很耗时的动作,则应该设法把这个动作移到同步区域的外面。
常见的比如我们进行事务操作的时候应该尽可能减少事务代码块中的逻辑。不要把数据转换等无关逻辑放在同步事务块中。
3. executor、task和 stream 优先于线程
Java平台中已经增加了java.util.concurrent。 这个包中包含了一个Executor Framework它是一个很灵活的基于接口的任务执行工具。因此不仅应该尽量不要编写自己的工作队列,而且还应该尽量不直接使用线程。
Alibaba开发手册禁止使用
Executors,推荐使用ThreadPoolExecutor。因为Executors工厂类创建出来的线程池参数不明确,比如最大线程数的设置。这会导致潜在的风险,建议使用ThreadPoolExecutor显式设置参数,更明确。
4. 并发工具优先于 wait 和 notify
从 Java 5发行版本开始,Java平台就提供了更高级的并发工具,它们可以完成以前必须在
wait和notify上手写代码来完成的各项工作。既然正确地使用wait和notify比较困难,就应该用更高级的并发工具来代替。
并发集合为标准的集合接口(如List、Queue和Map)提供了高性能的并发实现。为了提供高并发性,这些实现在内部自己管理同步。因此,并发集合中不可能排除并发活动。将它锁定没有什么作用,只会使程序的速度变慢。
因此,应该优先使用ConcurrentHashMap,而不是使用Collections.synchronizedMap。
同步器是使线程能够等待另一个线程的对象,允许它们协调动作。最常用的同步器是
CountDownLatch和Semaphore。较不常用的是CyclicBarrier和Exchanger。功能最强大的同步器是 Phaser。
应该优先使用System.nanoTime,而不是使用System.currentTimeMillis。 因为System.nanoTime更准确,它不受系统的实时时钟的调整所影响 。
由于Java加入了广泛通用的并发工具,所以没有理由在新代码中使用wait方法和notify方法来手动控制同步。
5. 线程安全性的文档化
一个类为了可被多个钱程安全地使用,必须在文档中清楚地说明它所支持的线程安全性级别。
每个类都应该利用字斟句酌的说明或者线程安全注解,清楚地在文档中说 明它的线程安全属性。
有条件的线程安全类 必须在文档中指明“哪个方法调用序列需要外部同步,以及在执行这些序列的时候要获得哪 把锁”。如果你编写的是无条件的线程安全类,就应该考虑使用私有锁对象来代替同步的方法。
常见的情形:
- 不可变的:这个类的实例是不变的。所以,不需要外部的同步。这样的例子包括String、Long、Biginteger。
- 无条件的钱程安全:这个类的实例是可变的,但是这个类有着足够的内部同步,所以它的实例可以被并发使用,无须任何外部同步。其例子包括AtomicLong、ConcurrentHashMap等。
- 有条件的结程安全:除了有些方法为进行安全的并发 使用而需要外部同步之外,这种线程安全级别与无条件的线程安全相同。 这样的例子包括
Collections.synchronized包装返回的集合,它们的迭代器要求外部同步。 - 非线程安全:这个类的实例是可变的。为了并发地使用它们,客户端必须利用自己选择的外部同步包围每个方法调用(或者调用序列)。这样的例子包括通用的集合实现,例如ArrayList、HashMap等。
- 线程对立的: 这种类不能安全地被多个线程并发使用,即使所有的方法调用都被外部同步包围。线程对立的根源通常在于,没有同步地修改静态数据。没有人会有意编写一个线程对立的类;这种类是因为没有考虑到并发性而产生的后果。当一个类或者方法被发现是线程对立的,一般会得到修正或者被标注为 “不再建议使用”。
6. 慎用延迟初始化
延迟初始化是指延迟到需要域的值时才将它初始化的行为。如果永远不需要这个值,这个域就永远不会被初始化。除非绝对必要,否则就不要这么做。
在大多数情况下,正常的初始化要优先于延迟初始化。
如果利用延迟优化来破坏初始化的循环, 就要使用同步访问方法。
private List<Integer> dataList;
public List<Integer> getData() {
if (dataList == null) {
// 同步初始化 dataList
synchronized (this) {
if (dataList == null) {
dataList = initializeDataList();
}
}
}
return dataList;
}
如果出于性能的考虑而需要对静态域使用延迟初始化,就使用
lazy initialization holde class模式。
当getField方法第一次被调用时,它第一次读取FieldHolder.field,导致FieldHolder类得到初始化。这种模式的魅力在于getField方法没有被同步,并且只执行一个域访问,因此延迟初始化实际上并没有增加任何访问成本。
private static class FieldHolder {
static final FieldType field = computeFieldValue();
}
private static FieldType getField() {
return FieldHolder.field;
}
如果出于性能的考虑而需要对实例域使用延迟初始化,就使用双重检查模式(
double check idiom)。
public class LazyInitializationExample {
// 延迟初始化的实例域
private volatile FieldType field;
// 获取实例域的方法
public FieldType getField() {
// 第一次检查
if (field == null) {
// 同步块
synchronized (this) {
// 第二次检查
if (field == null) {
// 进行初始化
field = new FieldType();
}
}
}
return field;
}
}
7. 不要依赖于线程调度器
线程调度器决定了哪些线程会运行以及会运行多长时间。但是每个操作系统采用的策略是不同的,我们的程序不应该依赖操作系统的线程调度策略。
任何依赖于线程调度器来达到正确性或者性能要求的程序,很有可能都是不可移植的。
比如调整线程优先级,线程优先级是Java平台上最不可移植的特征了。
不要让应用程序的正确性依赖于线程调度器。 否则,得到的应用程序将既不健壮,也不具有可移植性。
十一、序列化
1. 其他方法优先于Java序列化
序列化的根本问题在于,其攻击面过于庞大,无法进行防护,并且它还在不断地扩大: 对象图是通过在
ObjectIputStream上调用readObject方法进行反序列化的。 这个方法其实是个神奇的构造器,它可以将类路径上几乎任何类型的对象都实例化,只要该类型实现了Serializable接口。在反序列化字节流的过程中,该方法可以执行以上任意类型的代码,因此所有这些类型的代码都是攻击面的一部分。
避免序列化攻击的最佳方式是永远不要反序列化任何东西。在新编写的任何新系统中都没有理由再使用Java序列化。永远不要反序列化不被信任的数据。
序列化是很危险的,应该予以避免。 如果是重新设计一个系统,一定要用跨平台的结构化数据表示法代替,如 JSON或者protobuf。
2. 谨慎地实现 Serializable 接口
实现
Serializable接口而付出的最大代价是,一旦一个类被发布,就大大降低了 “改变这个类的实现”的灵活性。
比如我们将Person类实例序列化并存储到文件中:
public class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
public class SerializationExample {
public static void main(String[] args) {
Person person = new Person("吉娅", 12);
try (ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("person.ser"))) {
outputStream.writeObject(person);
System.out.println("Person object serialized successfully.");
} catch (IOException e) {
e.printStackTrace();
}
}
}
如果我们修Person类,增加一个新的字段email,此时,如果我们尝试从之前的序列化文件中反序列化 Person对象,就会出现反序列化异常。
public class Person implements Serializable {
private String name;
private int age;
private String email; // 新增的字段
public Person(String name, int age, String email) {
this.name = name;
this.age = age;
this.email = email;
}
}
实现
Serializable的第二个代价是,它增加了出现Bug和安全漏洞的可能性。
通常情况下,对象是利用构造器来创建的;序列化机制是一种语言之外的对象创建机制。依靠默认的反序列化机制,很容易使对象的约束关系遭到破坏,攻击者可以通过序列化控制和更改对象内部的信息。这些信息在通过构造器创建时是无法访问的。
实现
Serializable的第三个代价是,随着类发行新的版本,相关的测试负担也会增加。
当一个可序列化的类被修订的时候,很重要的一点是,要检查是否可以“在新版本中序列化一个实例,然后在旧版本中反序列化”。
为了继承而设计的类应该尽可能少地去实现Serializable接口, 用户的接口也应该尽可能少继承Serializable接口。如果违反了这条规则,扩展这个类或者实现这个接口的程序员就会背上沉重的负担。
3. 考虑使用自定义的序列化形式
如果事先没有认真考虑默认的序列化形式是否合适,则不要贸然接受。接受默认的序列化形式是一个非常重要的决定,需要从灵活性、性能和正确性等多个角度对这种编码形式进行考察。一般来讲,只有当自行设计的自定义序列化形式与默认的序列化形式基本相同时,才能接受默认的序列化形式。
举个例子来说明,假设有一个User类表示用户信息,其中包含用户名、年龄等字段。如果默认的序列化形式可以很好地描述User对象的状态,那么可以直接使用默认的序列化形式。但如果需要将用户的敏感信息如密码加密后才序列化,就需要设计一个自定义的序列化形式来实现这一点。如果在设计阶段未考虑到这一点,而直接使用了默认的序列化形式,那么在未来版本中想要改变序列化方式来加密密码就会很困难,因为默认的序列化形式已经被使用,更改会导致反序列化失败导致兼容性问题。
如果在读取整个对象状态的任何其他方法上强制任何同步,则也必须在对象序列化上强制这种同步。
如果一个类的某个方法需要在多线程环境下保证对象状态的一致性,那么在序列化该类的对象时,也需要考虑这种线程安全性,并采取相应的同步措施,以确保在序列化过程中对象状态的正确性。
private synchronized void writeObject(ObjectOutputStream s) throws IOException {
s.defaultWriteObject();
}
不管你选择了哪种序列化形式,都要为自己编写的每个可序列化的类声明一个显式的序列版本
UID。 这样可以避免序列版本UID成为潜在的不兼容根源。而且, 这样做也会带来小小的性能好处 。 如果没有提供显式的序列版本UID,就需要在运行时通过一个高开销的计算过程来产生一个序列版本UID。
private static final long serialVersionUID = XXX;
4. 保护性地编写readObject方法
在编写
readObject方法的时候,都要这样想:你正在编写一个公有的构造器,无论给它传递什么样的字节流,它都必须产生一个有效的实例。不要假设这个字节流一定代表着一个真正被序列化过的实例。
比如一个类:
这个类的构造方法约束了条件,但是直接使用反序列化来实例化对象会破坏这个约束条件,攻击者会用这种方法创造一个不可能的对象。所以要保护性的编写readObject方法。比如在readObject方法种进行约束条件检查,不符合条件将报错。
public final class Period {
private final Date start;
private final Date end;
public Period(Date start, Date end) {
this.start = new Date(start.getTime());
this.end = new Date(end.getTime());
// 约束实例化对象的条件
if (this.start.compareTo(this.end) > 0) {
throw new IllegalArgumentException(start + " after " + end);
}
}
}
5. 对于实例控制,枚举类型优先于readResolve
除了枚举单例之外的单例模式在实现序列化后会被破坏。因为反序列化时总会返回一个新的实例,所以推荐使用基于枚举的单例模式。基于枚举默认实现了Serializable接口同时枚举天然就是单例的,无法通过其他方式创建新的实例因此无法通过序列化和反序列化来破坏其单例特性。
如果需要一个既可序列化又是实例受控的类,那就要提供一个readResolve方法。
readResolve方法是在序列化和反序列化过程中用于替换从流中读取的对象的特殊方法。当对象被反序列化时,readResolve方法会被调用,并返回一个对象来替换从流中读取的对象。这样可以确保在反序列化后获得的对象是开发人员期望的对象。
我们可以用readResolve方法来避免序列化破坏单例,我们通常会返回事先定义好的单例对象,或者是枚举类型中的特定常量。这样在反序列化时,就可以直接获取到单例实例,而不会创建新的实例。
public class Singleton implements Serializable {
private static final Singleton INSTANCE = new Singleton();
private Singleton() {}
public static Singleton getInstance() {
return INSTANCE;
}
// 防止反序列化破坏单例
private Object readResolve() {
return INSTANCE;
}
}
6. 考虑用序列化代理代替序列化实例
要想稳健地将带有重要约束条件的对象序列化时可以考虑用序列化代理代替序列化实例。
⚠️ 但是这种方式的性能不高。
举个例子:
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
validateAge();
}
private void validateAge() {
// 约束条件
if (age < 0) {
throw new IllegalArgumentException("Age must be greater than or equal to zero");
}
}
private void readObject(ObjectInputStream stream) throws InvalidObjectException {
// 避免通过Person反序列化 避免破坏约束条件
throw new InvalidObjectException("Proxy required");
}
}
使用序列化代理:
public class PersonProxy implements Serializable {
private static final long serialVersionUID = 2L;
private final String name;
private final int age;
public PersonProxy(Person person) {
this.name = person.getName();
this.age = person.getAge();
}
private Object readResolve() throws ObjectStreamException {
// 实际上是通过构造实例化的Person 避免了直接反序列化破坏约束条件
return new Person(name, age);
}
}